Biography
Frost is a dedicated engineer and scientist in the field of image and video understanding, with the ultimate goal of giving people the AI power to build community and bring the world closer together. In 2023, Frost received his PhD degree at King Abdullah University of Science and Technology (KAUST) under the supervision of Professor Bernard Ghanem, where he worked on query localization in long-form videos. Prior to his graduate studies, Frost earned a bachelor’s degree from Zhejiang University, College of Optical Science and Engineering. Frost also enjoys learning to play Guqin in his free time.
Please email xu.frost[at]gmail.com for the up-to-date CV.
- Video Understanding
- Video Generation
MS/PhD in Electrical and Computer Engineering, 2017 - 2023
King Abdullah University of Science and Technology
BSc in Opto-Elctronics Information Science and Engineering, 2013 - 2017
Zhejiang University
Skills
2013 - Present
2017 - Present
2020 - Present
Experience
Featured Publications
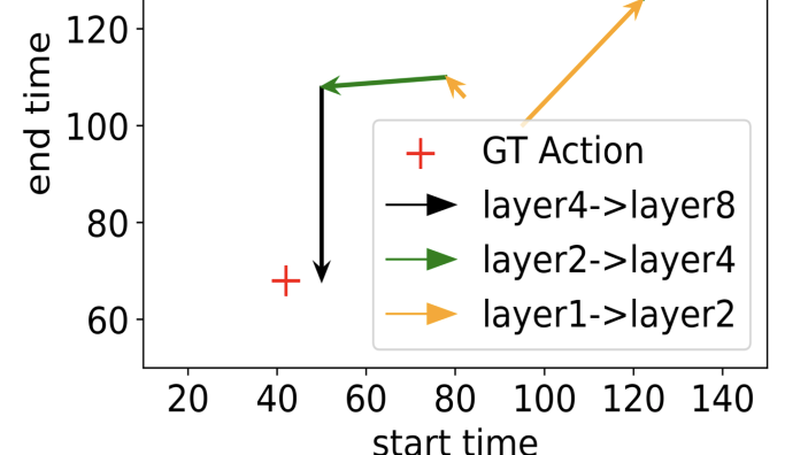

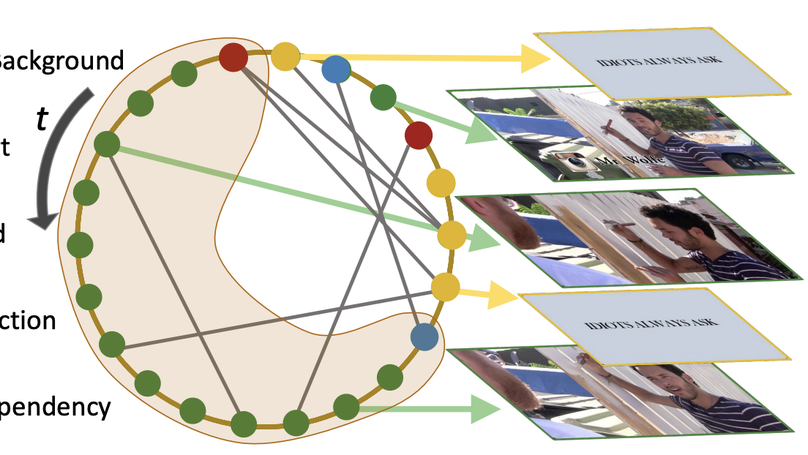
Temporal action detection is a fundamental yet challenging task in video understanding. Video context is a critical cue to effectively detect actions, but current works mainly focus on temporal context, while neglecting semantic context as well as other important context properties. In this work, we propose a graph convolutional network (GCN) model to adaptively incorporate multi-level semantic context into video features and cast temporal action detection as a sub-graph localization problem. Specifically, we formulate video snippets as graph nodes, snippet-snippet correlations as edges, and actions associated with context as target sub-graphs. With graph convolution as the basic operation, we design a GCN block called GCNeXt, which learns the features of each node by aggregating its context and dynamically updates the edges in the graph. To localize each sub-graph, we also design a SGAlign layer to embed each sub-graph into the Euclidean space. Extensive experiments show that G-TAD is capable of finding effective video context without extra supervision and achieves state-of-the-art performance on two detection benchmarks. On ActityNet-1.3, we obtain an average mAP of 34.09%; on THUMOS14, we obtain 40.16% in mAP@0.5, beating all the other one-stage methods.
Recent Publications
Contact
- xu[dot]frost[at]gmail.com
- London, NW1