G-TAD: Sub-Graph Localization for Temporal Action Detection
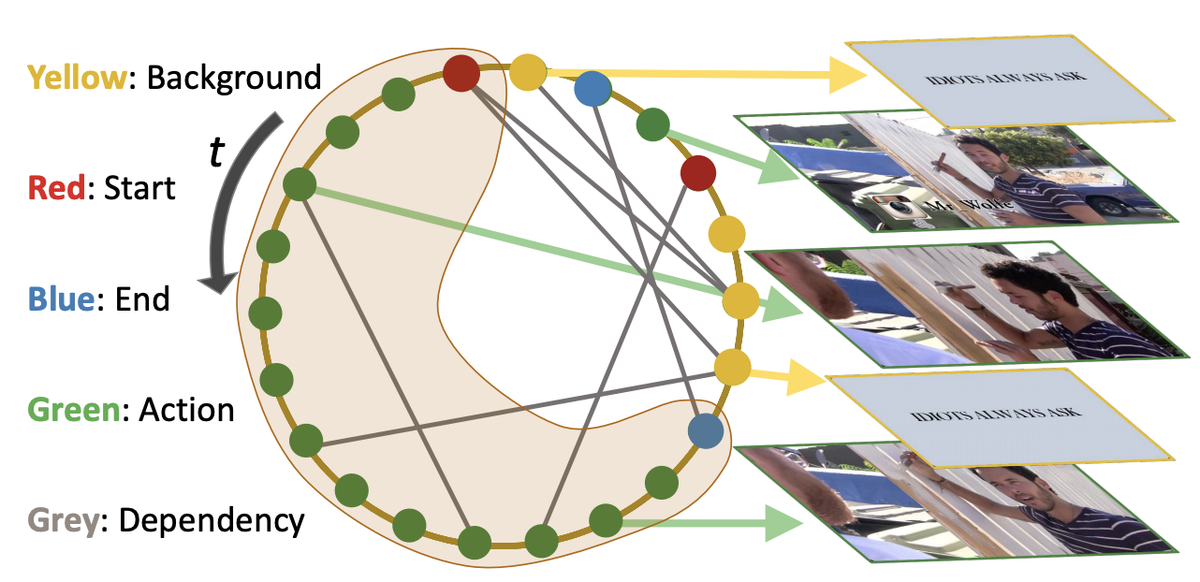 Graph formulation of a video. Nodes: video snippets (a video snippet is defined as consecutive frames within a short time period). Edges: snippet-snippet correlations. Sub-graphs: actions associated with context. There are 4 types of nodes: action, start, end, and background, shown as colored dots. There are 2 types of edges: (1) temporal edges, which are pre-defined according to the snippets’ temporal order; (2) semantic edges, which are learned from node features.
Graph formulation of a video. Nodes: video snippets (a video snippet is defined as consecutive frames within a short time period). Edges: snippet-snippet correlations. Sub-graphs: actions associated with context. There are 4 types of nodes: action, start, end, and background, shown as colored dots. There are 2 types of edges: (1) temporal edges, which are pre-defined according to the snippets’ temporal order; (2) semantic edges, which are learned from node features.Abstract
Temporal action detection is a fundamental yet challenging task in video understanding. Video context is a critical cue to effectively detect actions, but current works mainly focus on temporal context, while neglecting semantic context as well as other important context properties. In this work, we propose a graph convolutional network (GCN) model to adaptively incorporate multi-level semantic context into video features and cast temporal action detection as a sub-graph localization problem. Specifically, we formulate video snippets as graph nodes, snippet-snippet correlations as edges, and actions associated with context as target sub-graphs. With graph convolution as the basic operation, we design a GCN block called GCNeXt, which learns the features of each node by aggregating its context and dynamically updates the edges in the graph. To localize each sub-graph, we also design a SGAlign layer to embed each sub-graph into the Euclidean space. Extensive experiments show that G-TAD is capable of finding effective video context without extra supervision and achieves state-of-the-art performance on two detection benchmarks. On ActityNet-1.3, we obtain an average mAP of 34.09%; on THUMOS14, we obtain 40.16% in mAP@0.5, beating all the other one-stage methods.