Low-Fidelity End-to-End Video Encoder Pre-training for Temporal Action Localization
Abstract
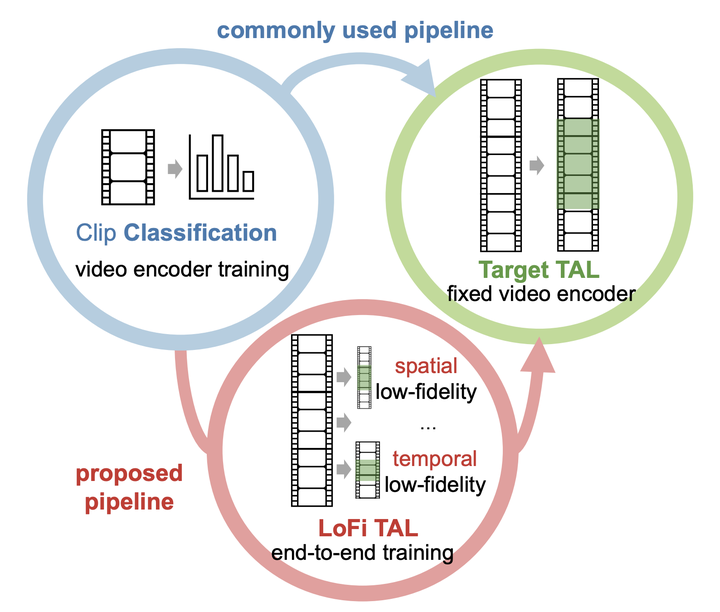
Temporal action localization (TAL) is a fundamental yet challenging task in video understanding. Existing TAL methods rely on pre-training a video encoder through action classification supervision. This results in a task discrepancy problem for the video encoder – trained for action classification, but used for TAL. Intuitively, end-to-end model optimization is a good solution. However, this is not operable for TAL subject to the GPU memory constraints, due to the prohibitive computational cost in processing long untrimmed videos. In this paper, we resolve this challenge by introducing a novel low-fidelity end-to-end (LoFi) video encoder pre-training method. Instead of always using the full training configurations for TAL learning, we propose to reduce the mini-batch composition in terms of temporal, spatial or spatio-temporal resolution so that end-to-end optimization for the video encoder becomes operable under the memory conditions of a mid-range hardware budget. Crucially, this enables the gradient to flow backward through the video encoder from a TAL loss supervision, favourably solving the task discrepancy problem and providing more effective feature representations. Extensive experiments show that the proposed LoFi pre-training approach can significantly enhance the performance of existing TAL methods. Encouragingly, even with a lightweight ResNet18 based video encoder in a single RGB stream, our method surpasses two-stream ResNet50 based alternatives with expensive optical flow, often by a good margin.